使用Embedding策略在各种任务场景中提取用户信息的paper
《Modeling User Activities on the Web using Paragraph Vector》
:用户在浏览网页的时候会留下来一系列的行为,比方说网页浏览,搜索问题,点击广告等,设用户$i$留下的 $T$个行为表示为$(a{i,1},a{i,2}….,a_{i,Ti})$
)。我们希望根据所有的用户行为数据,生成表征每一个用户的向量,使具有相同行为序列的用户被映射到相似的向量空间之中。我们希望根据所有的用户行为数据,生成表征每一个用户的向量,使具有相同行为序列的用户被映射到相似的向量空间之中。
该论文借鉴了skip-gram 的思想
Deep & Cross Network for Ad Click Predictions
https://blog.csdn.net/Dby_freedom/article/details/86502623
https://blog.csdn.net/qq_40778406/article/details/105009989
https://www.cnblogs.com/LuckPsyduck/p/11995230.html
https://zhuanlan.zhihu.com/p/96010464
RankNet
https://www.cnblogs.com/kemaswill/p/kemaswill.html
2019-09-06 15:37:39
vin word2vec # word2vec
标签(空格分隔): word2vec
![word2word][1]
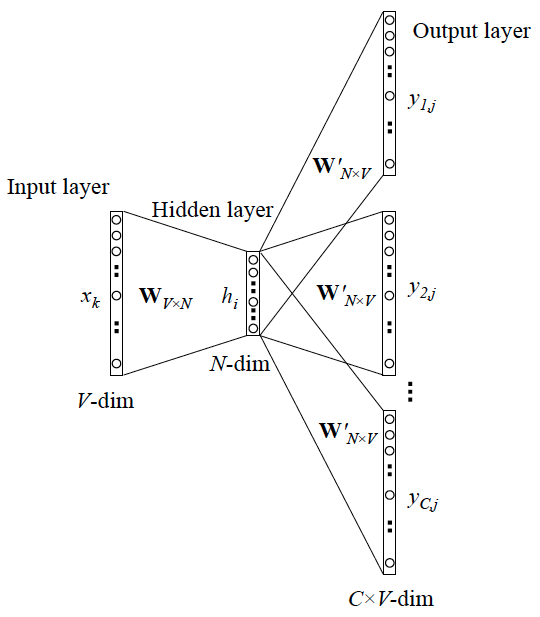
对于上图,以前直觉对于skip-gram模型,有这样一个疑问
比如:
词汇表有V个,所以我们的输入是V-dimension的向量,对于句子:
“what are you doing now”
对于skip-gram方式:
输入 x 是 you 的one-hot向量,
输出 y 是 V 维度向量,这个向量可以直接把what, are, doing, now四个词的index位置点亮唯1,然后计算损失函数,这样的方式不是更好吗?
某天回看word2vec模型结构图突然明白,这是不合理的,因为context是有“序”的信息的,如果类似bag-of-words的方式处理,所达到的效果只关注word是否出现,而丢掉了序的信息。
所以正确的网络结构应该是这样的:
![skip-gram][2]
[2]: https://pic1.zhimg.com/80/v2-ca81e19caa378cee6d4ba6d867f4fc7c_hd.jpg 2019-09-12 10:25:43
{kind=link}
CTR
Deep Interest Network
《Deep Interest Network for Click-Through Rate Prediction》
【传送门】
总结:
用户有多个兴趣爱好,访问了多个 good_id,shop_id。为了降低纬度并使得商品店铺间的算术运算有意义,我们先对其进行 Embedding 嵌入。那么我们如何对用户多种多样的兴趣建模那?使用 Pooling 对 Embedding Vector 求和或者求平均。同时这也解决了不同用户输入长度不同的问题,得到了一个固定长度的向量。这个向量就是用户表示,是用户兴趣的代表。
但是,直接求 sum 或 average 损失了很多信息。所以稍加改进,针对不同的 behavior id 赋予不同的权重,这个权重是由当前 behavior id 和候选广告共同决定的。这就是 Attention 机制,实现了 Local Activation。
DIN 使用 activation unit 来捕获 local activation 的特征,使用 weighted sum pooling 来捕获 diversity 结构。
在模型学习优化上,DIN 提出了 Dice 激活函数、自适应正则 ,显著的提升了模型性能与收敛速度。
参考资料
Deep Interest Network for Click-Through Rate Prediction
Learning piece-wise linear models from large scale data for ad click prediction
BPR
Here $\hat{x}_{u i j}(\Theta)$ is an arbitrary real-valued function of
the model parameter vector $\Theta$ which captures the special relationship between user $u$, item $i$ and item $j$.
Here,$>u$ is the desired but latent preference structure
for user u. All users are presumed to act independently
of each other.
https://cloud.tencent.com/developer/article/1164759
排序推荐算法大体上可以分为三类,第一类排序算法类别是点对方法(Pointwise Approach),这类算法将排序问题被转化为分类、回归之类的问题,并使用现有分类、回归等方法进行实现。第二类排序算法是成对方法(Pairwise Approach),在序列方法中,排序被转化为对序列分类或对序列回归。所谓的pair就是成对的排序,比如(a,b)一组表明a比b排的靠前。第三类排序算法是列表方法(Listwise Approach),它采用更加直接的方法对排序问题进行了处理。它在学习和预测过程中都将排序列表作为一个样本。排序的组结构被保持
我们构造的训练数据是
总结
1.BPR是基于矩阵分解的一种排序算法,它不是做全局的评分优化,而是针对每一个用户自己的商品喜好分贝做排序优化。
2.它是一种pairwise的排序算法,对于每一个三元组
3.同时,引入了贝叶斯先验,假设参数服从正态分布,在转换后变为了L2正则,减小了模型的过拟合