Classification
对数据进行shuffling, 因为某些算法对数据的顺序比较敏感。但有些数据则需要保持这种顺序,比如说股票或天气数据。
np.random.seed(n),确保每次随机数相同,经过测试,即使关闭python重新打开程序,使用同样的seed情况下,获取到的随机数仍然保持一致,这对于重现实验结果很有帮助,上一次对trian set 如何shuffling,这一次依旧保持一致。
样本的标签使用tuple保证在处理数据时不被更改。
Precision and Recall

recall“召回率”这个含义很好理解,例如召回有质量问题汽车这一情况,算法在判别有问题时偏重检测了发动机,因此最后的结果只召回了发动机有问题的样本,而其他零件有问题的没有召回,最后在统计召回率这一指标中便可发现问题。
权衡准确率和召回率要应对不同问题,比如说过判别疑犯,寻求的是high recall,precison低一些没关系,俗话说宁可错杀千万不可漏掉一个便是如此,当然在这个情况中,进一步二次审查即可,通俗点说,即尽可能找出(“召回”)目标正例;再比如判定一个视频是否对儿童安全,重视的是high precision,recall低一些没关系。

关于precison 和 recall在threshold变化下各自的走向。随着thershold增加,recall降低是因为positive samples越累越少,分子分母同时减少相同数值(糖水原理反推,浓度即降低),整体减少。precision则不一定,因为分子分母减少并不一定相同,有可能FP(false positive)也减少了。
Performance Measures
Confusion Matrix
Precision and Recall
ROC Curve
Lasso, Group Lasso, Ringe
https://leimao.github.io/blog/Group-Lasso/
Suppose $\beta$ is a collection of parameters. $\beta=\left{\beta{1}, \beta{2}, \cdots, \beta{n}\right}$, The L0, L1, and L2 norms are denoted as $|\beta|{0},|\beta|{1},|\beta|{2}$. They are defined as:
Given a dataset ${X, y}$ where $X$ is the feature and $y$ is the label for regression, we simply model it as has a linear relationship $y=X \beta$. With regularization, the optimization problem of L0, Lasso and Ridge regressions are
![此处输入图片的描述][2]
Group Lasso
Suppose the weights in $\beta$ could be grouped, the new weight vector becomes $\beta_{G}=\left{\beta^{(1)}, \beta^{(2)}, \cdots, \beta^{(m)}\right} .$ Each $\beta^{(l)}$ for $1 \leq l \leq m$ represents a group of weights from $\beta$.
We further group $X$ accordingly. We denote $X^{(l)}$ as the submatrix of $\mathrm{X}$ with columns corresponding to the weights in $\beta^{(l)}$. The optimization problem becomes
where $p_{l}$ represents the number of weights in $\beta^{(l)}$.
It should be noted that when there is only one group, i.e., $m=1$, Group Lasso is equivalent to Ridge; when each weight forms an independent group, i.e., $m=n$, Group Lasso becomes Lasso.
Sparsity
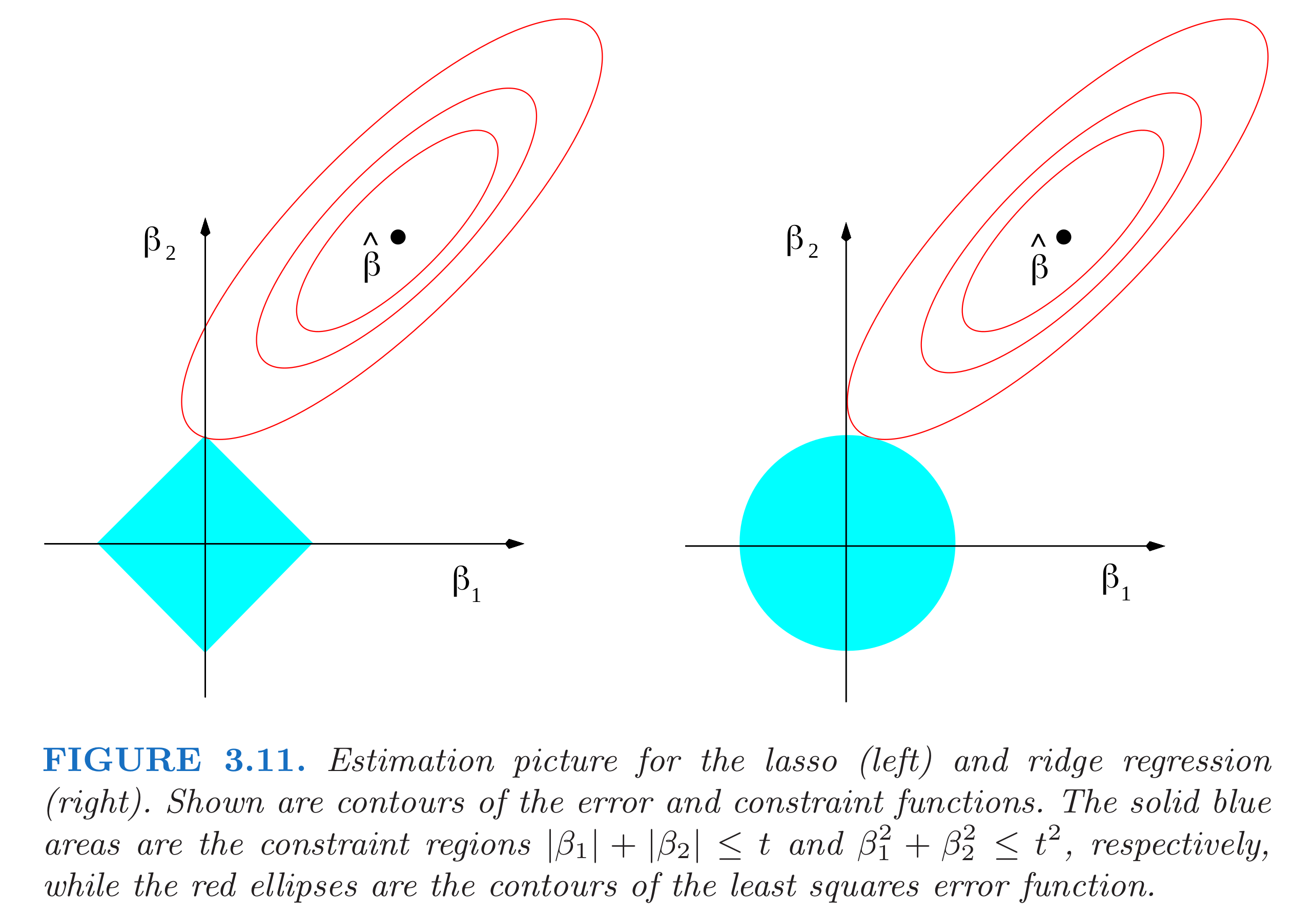
The most intuitive explanation to the sparsity caused by Lasso is that the non-differentiable corner along the axes in the Lasso $|\beta|{1}$ are more likely to contact with the loss function $|y-X \beta|{2}^{2}$. In Ridge regression, because it is differentiable everywhere in the Ridge $|\beta|_{2}$, the chance of contact along the axes is extremely small.
[2]: https://leimao.github.io/images/blog/2020-02-13-Group-Lasso/lasso-vs-ridge.png 2020-07-13 16:54:13
{kind=link}